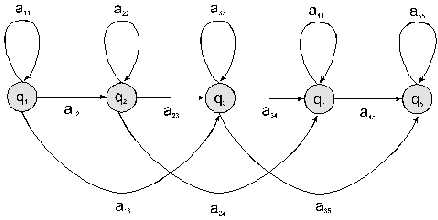
3. Stufe: Hidden Markov ModellAufgabe der 3. Stufe meines Klangerkennungssystems ist es, zu einer ausgewählten Sequenz von Punkten auf der topologischen Karte (einem Klangereignis) ähnliche Sequenzen innerhalb der gesamten Abfolge (Audiodatei) zu finden. Dies läßt sich mit einem sogenannten Hidden Markov Modell realisieren, einem stochastischen Modell, das im Bereich der automatischen Spracherkennung häufig zur Klassifizierung von Phonem- und Wortfolgen eingesetzt wird. Grundlage für das Hidden Markov Modell ist die Markov-Kette, ein stochastischer Automat, der ausgehend vom aktuellen Zustand mit einer gewissen Wahrscheinlichkeit in einen anderen Zustand übergeht (vgl. Abb. 2). Dabei hängt die Übergangswahrscheinlichkeit immer nur vom aktuellen Zustand und nicht von vorhergehenden Zuständen ab (Markov-Bedingung).
Beim Hidden Markov Modell kommt noch eine weitere Ebene – die Beobachtungssequenz – hinzu, die mit der darunterliegenden, für den Beobachter verborgenen Markov-Kette wiederum über eine Wahrscheinlichkeitsfunktion (Ausgabewahrscheinlichkeit) verknüpft ist. Es handelt sich daher um einen doppelt stochastischen Prozeß9
Ein HMM wird im Wesentlichen durch drei Größen charakterisiert:
In meinem System entspricht die Beobachtungssequenz einer Abfolge von Punkten auf der topologischen Karte. Um ähnliche Sequenzen mit einem HMM erkennen |