differently. In the first case we allow non-negative values as well as negative ones. Positive values express >inhibitions< for the corresponding transitions, while nagative values express >attractions<. In the second case we allow non-negative values only. We use the following notation and terminology:
- A map
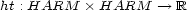 is called a harmonic tensor. In this case we have in mind that its values quantify transitions in terms of inhibitions (non-negative values) and attractions (negative values). We speak of para-pseudo-distance, if all
is called a harmonic tensor. In this case we have in mind that its values quantify transitions in terms of inhibitions (non-negative values) and attractions (negative values). We speak of para-pseudo-distance, if all 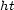 is symmetric (i.e.
is symmetric (i.e. 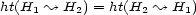 , for all loci
, for all loci 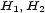 ) and positive semi-definite, i.e.
) and positive semi-definite, i.e. 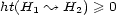 and
and 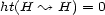 for all loci
for all loci 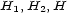 . A para-pseudo-distance is called a pseudo-distance if further the triangle-inequality
. A para-pseudo-distance is called a pseudo-distance if further the triangle-inequality 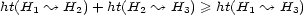 is satisfied for all
is satisfied for all 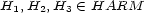 . It is called a para-distance, if it is positive definite (i.e.
. It is called a para-distance, if it is positive definite (i.e. 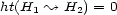 if and only if
if and only if 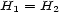 ). Finally,
). Finally, 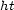 is called a distance (or a metric), if it is a pseudo-distance and a para-distance.
is called a distance (or a metric), if it is a pseudo-distance and a para-distance. - A map
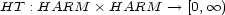 is called a harmonic transition value map. In this case we have in mind that its values directly quantify transitions in a monotonous way. If the image of
is called a harmonic transition value map. In this case we have in mind that its values directly quantify transitions in a monotonous way. If the image of 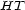 is actually
is actually ![[0,1]](../graphic/Co7373x.gif) we call it a para-probability map. If further
we call it a para-probability map. If further 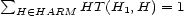 for all
for all 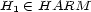 we speak of a semi-probability-map and if in addition we have
we speak of a semi-probability-map and if in addition we have 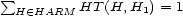 for all
for all 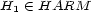 we speak of a probability-map.
we speak of a probability-map.
We use the exponential/logarithmic functions in order to formally translate the two kinds of quantification into one another: Suppose, we are given a harmonic tensor 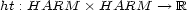 . Its associated harmonic transition value map
. Its associated harmonic transition value map 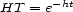 is defined by
is defined by
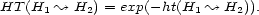
Conversely, if we are given a harmonic transition value map
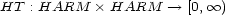
, then its associated transition value map
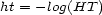
is defined by
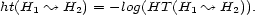
Non-negative harmonic tensors (including para-pseudo-distances) formally correspond to para-probability-maps. However, we do not intend to project an ontological interpretation onto this correspondence.
1.4 Evaluation of Harmonic Analyses
We now discuss a numeric evaluation method for harmonic analyses 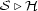 as well a suitable algorithm for the determination of best analyses for a fixed chord sequence
as well a suitable algorithm for the determination of best analyses for a fixed chord sequence 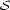 and varying pathways
and varying pathways 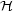 . The algorithm is called Viterbi algorithm and is used in the context of Hidden Markov Models in order to calculate a most probable process in accordance with a sequence of observations. Readers which are familiar with such models will notice that such a probabilistic interpretation can be seen
. The algorithm is called Viterbi algorithm and is used in the context of Hidden Markov Models in order to calculate a most probable process in accordance with a sequence of observations. Readers which are familiar with such models will notice that such a probabilistic interpretation can be seen