Dieser Prozeß wird stochastisch als Wahrscheinlichkeitsverteilung dargestellt. Wenn
man unbegrenzt viele Daten zur Verfügung hat, z.B. bei leicht zugänglichen natürlichen
oder technischen Prozessen, kann man der tatsächlichen Verteilung beliebig
nahe kommen, indem man die Zahl der Beispiele erhöht. In der Praxis ist dies
allerdings selten möglich, da normalerweise die Daten nur beschränkt verfügbar
oder schwer zugänglich sind und der Berechnungsaufwand begrenzt werden
muß.
Eine Technik, um die Komplexität des Modells anzupassen, ist die Regularisierung.
Regularisierung bedeutet, zusätzlich zur Fehlerfunktion E einen Term 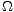 zu verwenden,
der ein Komplexitätsmaß darstellt, und die Summe von Fehler und Komplexitätsmaß zu
minimieren:
zu verwenden,
der ein Komplexitätsmaß darstellt, und die Summe von Fehler und Komplexitätsmaß zu
minimieren:
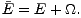 | (5.13) |
Dieser Term wird für MLPs üblicherweise als die Summe aller Gewichte definiert und
diese Art der Regularisierung Weight Decay genannt:
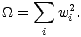 | (5.14) |
Damit wird ein Modell mit geringen Gewichten gegenüber einem mit hohen
Gewichten bevorzugt. Ein Modell mit kleineren Gewichten zu bevorzugen ist
sinnvoll, da die üblicherweise verwendete sigmoide Aktivierungsfunktion im
Bereich geringer Aktivierung näherungsweise linear ist, d.h. das Modell ist
einfacher als im nichtlinearen Bereich. Weight Decay hält auch den Beitrag
eines Teils der Gewichte vernachlässigbar klein, so daß weniger Verbindungen
effektiv zum Gesamtergebnis beitragen, das Modell also wiederum einfacher
wird. Der positive Effekt von Weight Decay ist zunächst empirisch festgestellt
worden.21
Weight Decay ist aber auch mit einer wahrscheinlichkeitstheoretischen Interpretation von
Backpropagation als Bayesschem Lernen verträglich, die im nächsten Abschnitt
behandelt wird.
5.1.6. Neuronale Netze als statistische Modelle
Neuronale Netze wurden in den letzten Jahren zunehmend unter dem Aspekt statistischer
Modellierung betrachtet und das Lernen des Netzes wahrscheinlichkeitstheoretisch
interpretiert. Hier sollen einige Zusammenhänge kurz dargestellt werden, die für
diese Arbeit von Bedeutung sind; eine ausführliche Darstellung findet sich bei
Bishop.22
Man betrachtet den Zusammenhang von Eingabedaten xi und Ausgabedaten ti als
Wahrscheinlichkeitsdichte p(x,t) = p(t|x)p(x). Für den Fall eines Regressionsproblems
geht man davon aus, daß es eine zu approximierende Funktion f(x) gibt, zu der sich in
den Daten zufällige Abweichungen 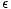 addieren:
addieren:
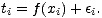 | (5.15) |