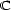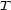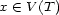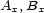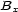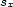|
These weights are obtained by aggregating local and global features at different levels of details. From the point of view of a composer or a performer this is a natural approach: Composition and performance are results of shaping processes at different levels of refinement. For instance, a performer may rehearse the general tempo of a piece as a whole and then refine the performance at increasingly detailed levels. Evidently, the actual sequence in which the various levels are emphasized during the rehearsing process varies individually. The ultimate result is an aggregation of all levels in one performance. More precisely, the music score has a natural hierarchical structure. Namely, it is commonly decomposed into periods, each period into bars, each bar into chords and notes. If necessary one can even divide up periods in smaller intermediate pieces, the same for bars. In any case one can naturally produce a tree from each given score. The main idea of Mazzola’s approach to a performance grammar (see Mazzola, 1995) is that this tree should canonically simulate the learning method of the interpreter: one first analyzes a period, then one refines the knowledge of the score through an analysis of its bars, and so on. At the end of this learning process the musician should produce the performance that the public listens to. We present here a mathematical model of this process. It is based on a family of linear representations of a special type of quivers (directed multigraphs) which we call the stemma quiver. Definition 1 The stemma quiver is a finite directed graph In order to define the stemma quiver |
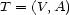
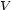
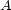
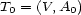

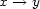
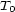




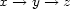





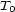

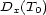

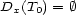
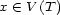
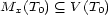


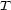
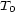

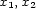

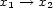
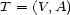
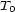
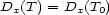
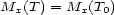
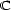 -stemma
-stemma