The first constraint states that inside a voice, a pattern a the correct number of onsets, that is, there are not two onsets at the same time. It can be written 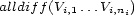 , so that the pattern is not degenerated. We could eliminate this constraint by taking the durations as variables and removing
, so that the pattern is not degenerated. We could eliminate this constraint by taking the durations as variables and removing  from the domains, but it would make the second constraint more complex (as a capacity constraint).
from the domains, but it would make the second constraint more complex (as a capacity constraint).
Second constraint, we must never hear two onsets at the same time, during a fixed duration 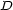 . It can be written : for two different voices,
. It can be written : for two different voices, 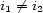 , two onsets
, two onsets 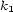 and
and 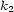 and for all
and for all 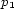 such that
such that 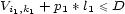 (the onset is repeated while it doesn’t exceed the duration),
(the onset is repeated while it doesn’t exceed the duration),
![Vi1,k1 + p1 * l1[l2] /= Vi2,k2](../graphic/Co4602x.gif)
An important parameter of this CSP is the average density of onsets. A density of  means that we hear in average one onset per two time units. Of course, it fixes the number of onsets by pattern, that is the number of variables for our CSP. There is obviously no solution when the density of onsets becomes too big.
means that we hear in average one onset per two time units. Of course, it fixes the number of onsets by pattern, that is the number of variables for our CSP. There is obviously no solution when the density of onsets becomes too big.
Independently of the CP resolution, we can study this problem thanks to the Chinese Remainder Theorem. In a particular case with two voices, and only one onset by voice, the goal is to find 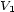 et
et 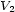 such that
such that
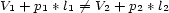
This exactly the negation of the chinese theorem, ie solve ![x = V1[l1]](../graphic/Co4607x.gif) et
et ![x = V2[l2]](../graphic/Co4608x.gif) with
with 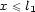 et
et 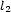 . So there exists a unique solution
. So there exists a unique solution 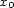 in
in ![[0,ppcm(l1,l2)]](../graphic/Co4612x.gif) , given by the formula
, given by the formula 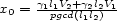 , where
, where 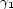 and
and 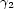 are the Bezout coefficient of
are the Bezout coefficient of 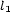 and
and 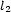 , ie
, ie 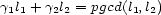 . These two values are given, so we simply have to find
. These two values are given, so we simply have to find 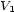 and
and 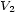 such that
such that 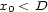 , ie solve
, ie solve
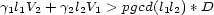
It is possible to generalize to  voices, although it is unfortunately not the same generalization as the chinese theorem with
voices, although it is unfortunately not the same generalization as the chinese theorem with  equations. Our goal is now to solve the system
equations. Our goal is now to solve the system ![x = Vi1[li1]](../graphic/Co4625x.gif)
![x = Vi2[li2]](../graphic/Co4626x.gif) for
for 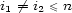 .
.
