Quadratsumme, denn dieses Verfahren entspricht bereits einer Minimierung des
CE-Fehlers.
Das Training mit den Beispielen aus dem letzten Abschnitt wurde für die FLN und
MLP mit CE-Fehlermaß mit logistischer Aktivierungsfunktion des Komparatorneurons
erneut durchgeführt. Tabelle 12.2 zeigt die Ergebnisse des Trainings. Auch hier wurde
die Aktivierung auf 0 gesetzt, wenn die Netzeingabe größer als 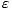 war, d.h. nur die
Beispiele wurden trainiert die falsch oder ›beinahe falsch‹ klassifiziert wurden. Für die
fuzzy-logischen Netze führt dies zu ähnlichen Ergebnissen wie die Quadratsumme und
semilineare Funktion. Ein Test, in dem auch alle korrekt bewerteten Beispiele in das
Training einbezogen wurden, führte für die FLN nicht zu einer Verbesserung der
Trainingsergebnisse.
war, d.h. nur die
Beispiele wurden trainiert die falsch oder ›beinahe falsch‹ klassifiziert wurden. Für die
fuzzy-logischen Netze führt dies zu ähnlichen Ergebnissen wie die Quadratsumme und
semilineare Funktion. Ein Test, in dem auch alle korrekt bewerteten Beispiele in das
Training einbezogen wurden, führte für die FLN nicht zu einer Verbesserung der
Trainingsergebnisse.
|
|
|
|
|
| | | | FLN1 | FLN2 | FLN3 | MLP4 | MLP3/3 |
|
|
|
|
|
| |
Interpretationsfehler
Trainingsmenge
| 6 | 8 | 8 | 8 | 3 |
| | (12%) | (16%) | (16%) | (16%) | (6%) |
|
|
|
|
|
| | Fehlerbetrag
(Quadratsumme) | 3.94e-7 | 5.58e-7 | 5.85e-7 | 3.19e-7 | 1.16e-7 |
|
|
|
|
|
| | Relative Beispiele | 230 | 124 | 236 | 245 | 249 |
|
|
|
|
|
| |
Fehler
auf
den
relativen
Beispielen
| 26 | 55 | 52 | 23 | 17 |
| | (11%) | (44%) | (22%) | (9%) | (6%) |
|
|
|
|
|
| | Relative Beispiele
nach 50 Iterationen | 240 | 242 | 236 | 245 | 248 |
|
|
|
|
|
| | Erreichte lokale
Minima | 4 | 2 | 4 | 3 | 2 |
|
|
|
|
|
| |
Interpretationsfehler
Testmenge
| 11 | 12 | 12 | 13 | 14 |
| | (22%) | (24%) | (24%) | (26%) | (28%) |
|
|
|
|
|
| | |
| Tabelle 12.2: | Ergebnisse des Trainings mit verschiedenen Netztypen. Als
Fehlermaß wurde Cross-Entropie und als Aktivierungsfunktion die logistische
Funktion verwendet. Die Anzahl der relativen Beispiele wurde auf 5 pro absolutem
Beispiel begrenzt. |
|
Die Verwendung der Trainingsmethode für Klassifikationsaufgaben ergab insgesamt
keine Verbesserung der Ergebnisse. Die FLN zeigten insgesamt etwas schlechtere
Ergebnisse. Die MLP erzeugten mehr Fehler auf der Trainingsmenge als mit
Quadratsummenfehler, die Generalisierung für das MLP3/3 verbesserte sich, erreichte
aber nicht ganz das Niveau der FLN.
12.4. Wirkung der Netzparameter
Es gibt einige Parameter im Training, deren Wirkung im folgenden erörtert werden soll.
Sie betreffen Backpropagation sowie relatives und iteratives Training.