| | |
|
|
|
|
|
|
|
|
|
|
|
| | | | | | | | | |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| | |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| | | |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| | | | | | | |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
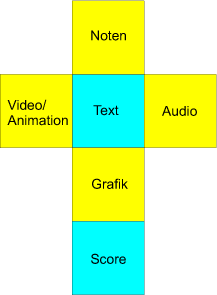
| Die in
Abbildung 17.2 dargestellten aufgeklappten sechs Seiten eines Würfels stellen
exemplarisch sechs einzunehmende Wissensperspektiven dar: Der Nutzer kann sich den
Content aus unterschiedlichen Blickwinkeln anschauen, z. B. text-, grafik- oder
soundbasiert.
Mit Hilfe eines Editors wird der Content eingegeben und schließlich in
XML2 |
Vgl. dazu Abschnitt 15.6.
|
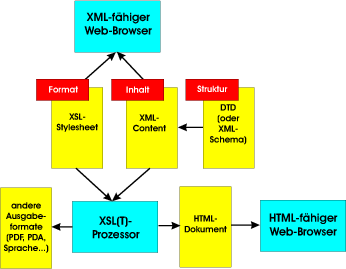
In der Abbildung 17.3 ist die Feinstruktur des ›Knowledge Cube‹ dargestellt. Der eigentliche Inhalt wird
in XML3 |
Die wesentlichen Vorteile von XML als Basisformat für den ›Knowledge Cube‹ wurden bereits in
Abschnitt 15.6 dargestellt.
|
|
DTD steht für ›Document Type Definition‹. Ausführlichere Informationen finden sich in Abschnitt
15.6.2.
|
|
|
|
|
|
|
|
|
|
|
|